
Inteligencia Artificial Generativa Local: Uso de Múltiples Modelos
04/09/2024 2024-09-04 17:02Inteligencia Artificial Generativa Local: Uso de Múltiples Modelos

Inteligencia Artificial Generativa Local: Uso de Múltiples Modelos
¿Te imaginas poder usar varios modelos de IA sin que estén en peligro tus datos y sin pagar una mensualidad? Más aún, imagina desarrollar un sistema para que otros usen IA en tu institución de manera segura y controlada sin tener que contar con la intervención de terceros. Este es el tercer artículo de mi proyecto en el que busco utilizar la inteligencia artificial generativa de manera local. Como mencioné en el artículo anterior, una de las principales ventajas de esta forma de usar IA es que no se necesitan proporcionar datos personales a una compañía externa ni pagar un servicio mensual. El objetivo es ofrecer recomendaciones sobre cómo las instituciones pueden implementar este servicio localmente para sus empleados, y en el caso de las universidades, para sus docentes y personal administrativo, de una manera más segura.
En esta ocasión, me complace compartir que he logrado añadir una interfaz gráfica amigable para el usuario. Tras evaluar varias opciones, opté por una que emula la interfaz de ChatGPT. Esta interfaz ofrece funciones similares, siempre y cuando el modelo utilizado lo permita.
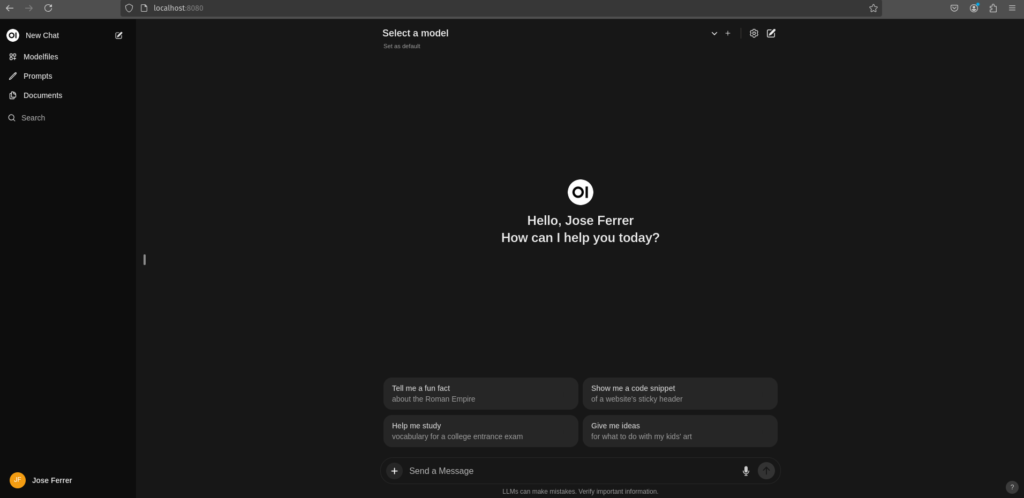
Repasando el Proceso
Para ejecutar modelos de IA se requiere una computadora o servidor con componentes más avanzados que una computadora personal estándar, aunque estos componentes ya no son tan costosos como lo eran hace dos años. Por ejemplo, en una conversación con un doctor, profesor universitario y un ingeniero de computadoras, mencioné que hoy en día puedo ejecutar el modelo de IA Mistral, que tiene 12 mil millones de parámetros, en la máquina que uso para este proyecto. Me comentó que en su laboratorio, que tiene un costo aproximado de un millón de dólares y equipos de hace dos años, no pudieron hacerlo. Esto ilustra cuánto se ha reducido el costo en relación con el poder de estas máquinas. La máquina que estoy utilizando costó alrededor de 5 mil dólares.
Una vez adquirida la máquina, instalé Pop!_OS, una versión de Ubuntu, que es un sistema operativo basado en Linux. Elegí esta versión porque está optimizada para las GPU de Nvidia, las cuales a su vez están optimizadas para tareas de IA. Explico que usar Linux representa una experiencia muy diferente en comparación con otros sistemas operativos. Como antiguo usuario de PC con Microsoft OS y más de una década usando MacOS de Apple, la transición a utilizar el “terminal” para instalar programas en Linux ha sido notable. En los sistemas operativos más tradicionales, las aplicaciones se descargan y se instalan a través de un asistente gráfico fácil de seguir. En Linux, en cambio, se utilizan comandos. Cabe señalar que es posible usar IA local en Microsoft OS y MacOS, pero se recomienda usar Linux por su eficiencia y compatibilidad con la IA.
Instalación de Modelos de IA
El siguiente paso es instalar un software que permita ejecutar los modelos de IA, ya sean Large Language Models (LLM) u otras. Los modelos no se ejecutan de manera independiente; requieren una infraestructura programática para funcionar. En este caso, utilicé Ollama, como expliqué en el artículo anterior de este blog. Este software me permitió instalar y ejecutar modelos como Llama 3, Phi y Mistral, que son tres LLM ampliamente utilizados. También instalé otros modelos adicionales. Al usar estos modelos en mi máquina, se ejecutan de manera rápida, comparable a ChatGPT. Durante las pruebas, el uso del GPU llegó hasta el 95% en algunos momentos. Esta GPU, una Nvidia 4060, tiene 24 GB de memoria con un bus de 384 bits. El procesador es un Intel i9 con 14 cores.
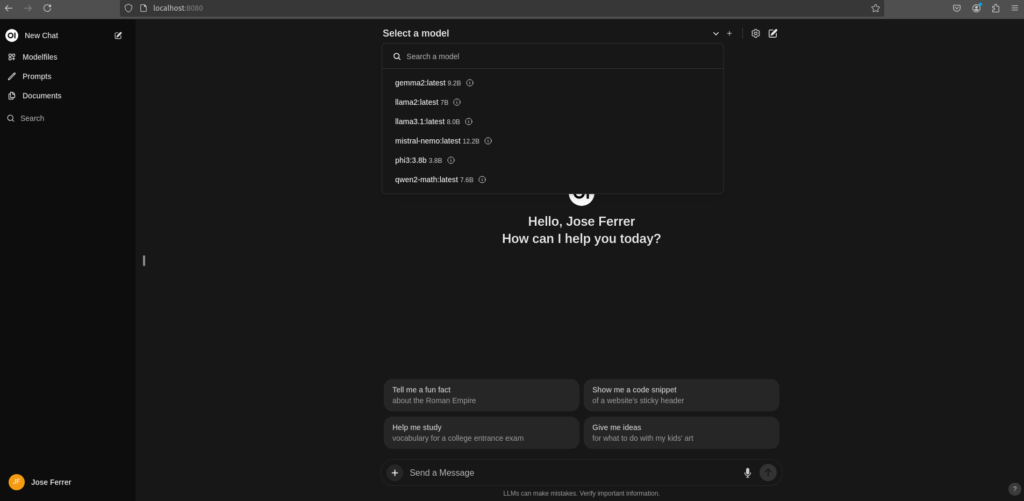
Ejecutar estos modelos de IA directamente desde el terminal de Linux no es una experiencia visualmente atractiva. Para mejorar la experiencia de usuario, opté por instalar una interfaz gráfica llamada WebUI, que facilita la ejecución de estos modelos de manera más simple. Con WebUI, no solo se pueden seleccionar los modelos, sino también combinar varios en una misma sesión de chat. Esto permite alternar fácilmente entre un LLM especializado en lenguaje narrativo, otro en análisis de datos, y otro más en matemáticas, por ejemplo. Estas características hacen que esta forma de ejecutar LLM sea muy útil para la productividad de investigadores, científicos de datos o docentes.
Próximos Pasos
El siguiente paso en este proyecto será añadir dos modelos más: Stable Diffusion y Flux. Finalmente, planeo dar acceso a otras personas en un entorno controlado, con identificación y contraseña de manera remota, una funcionalidad que ya permite WebUI. Con el proyecto avanzando, se hace evidente que, con una inversión razonable, las instituciones pueden instalar servidores propios y ofrecer acceso a estos modelos a su personal, evitando así pagar mensualidades por cada usuario y manteniendo sus datos bajo control.
